Research that informs our collective understanding of literacy development is not conducted within one field of science. This is tricky, because it means that researchers working in different areas aren’t necessarily speaking the same language. As such, it’s not always obvious how various strands of evidence are woven together to form a coherent picture of the ‘science of reading’.
So, let’s get detangling. What exactly do people investigate to answer questions related to literacy development?
First of all, there’s the type of science that describes…
The nature of the thing children learn
That is: language itself. Linguistics.
It is through studying language that researchers have tracked the etymological roots of our various writing systems. More broadly, linguists have taught us that the very origins of those writing systems are relatively recent, emerging somewhere around 5,000 years ago. This fact alone is important, because it means we humans are not biologically equipped to acquire literacy, and we can’t expect children to pick it up through exposure to text.
Beyond just looking at the history of languages, this kind of research is also conducted to detail the various characteristics of our English writing system, which – in the context of instruction – gives us an end goal for literacy acquisition.
By looking at a corpus of words that appear a lot in children’s literature, researchers can determine what percentage of words conform to a teachable phonics pattern (Gates & Yale, 2011; Johnston, 2001; Kearns, 2020). For example, Johnston (2001) showed that the letters ‘ay’ reliably represent the pronunciation of the first letter’s name in that pair (‘a’, or /eɪ/). The same convention (sometimes referred to in an instructional context as ‘when two vowels go walking, the first one does the talking’) applies to ‘ai’, ‘oa’, ‘ee’ and ‘ey’, though it isn’t generalisable on a broader scale – think of non-conformists like ‘oo’ and ‘au’.
As the above example demonstrates, our English orthography is complex, and some have argued that it’s too complex for phonics instruction to work. This is a question worth pondering: Why teach the conventions associated with phoneme-grapheme correspondences when there are so many inconsistencies and exceptions? Helpfully, a study by Vousden et al. (2011) puts these learning demands in context. Based on a large database of words contained in children’s books, there are far fewer phoneme-grapheme mappings to be learned than whole words or onset and rime chunks. This means it’s more efficient to learn the phonemes associated with letters ‘c’, ‘a’ and ‘t’ than to memorise the pronunciation of all whole words like ‘cat’ or all rimes like ‘at’.
This research is practically useful because knowing the statistical properties of a written language can help to guide what content should be presented to beginning readers. Note the word ‘guide’. The learning process itself is a factor to account for, and that process is the focus of research that looks at…
The nature of the thing children use to learn literacy
And that thing is, of course, the brain. Methods like electroencephalography (EEG) can be used to isolate the timing of neural activation at a very fine-grained level. Based on that kind of research, we know the approximate sequence of processing steps required for reading, from the reader’s first exposure to a printed word, to the identification of that word as a real word, to the word’s pronunciation and, eventually, the word’s associated meanings (Kutas & Federmeier, 2011; Marinkovic et al., 2003; ).
Not only that; we can isolate the approximate regions where those steps take place, using techniques like functional magnetic resonance imaging (fMRI). As mentioned earlier, the human brain wasn’t wired for reading, which means neural pathways have to be created to connect the visual processing regions with language processing regions. The central hub for these pathways is referred to as the ‘visual word form area’, and it is here that recognition of printed words takes place (Cohen et al., 2000; Dehaene, 2009).
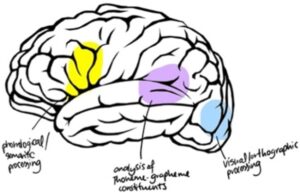
(based on Shaywitz, 2006)
One step removed from brain-based research is research into cognition and psychology. Here, neural processes are abstracted from their physical form (i.e., all the synapses and stuff) and studied as skills or behaviours. Such research is based on the premise that the mind and brain are inherently linked, and that ‘every time you observe a behavioural difference [(e.g., improved reading from Time A to Time B)], you must conclude that there is a neural difference underlying it’ (Protopapas, 2021).
Many studies have been conducted to examine the nature of learning in general (see Kirschner & Hendrick, 2020). Cognitive load theory, for example, has been based on decades of research into how children solve problems under various conditions. Specifically, problem-solving activities are seen to impose a heavy cognitive load if the student has no knowledge of the subject area and no familiarity with the steps needed to find a solution. In turn, this excess of mental effort interferes with learning. By way of contrast, direct guidance from an instructor reduces the working memory demands associated with a task, which therefore leads to better learning (Kirschner et al., 2016; Sweller, 1988).
There have also been a huge number of studies conducted in the field of cognitive psychology that look specifically at how children learn to read. As a recent example, Sargiani et al. (2021) compared word reading development in two groups of Portuguese-speaking 6-year-olds. Group 1 was trained on how to pronounce basic CV syllables (e.g., ma, me, mo, etc.) and Group 2 was trained on how to decode the phoneme-grapheme correspondences of those same syllables. The question was whether learning was influenced by the size of unit taught – syllable vs. grapheme. Results favoured the latter condition wherein children were taught phoneme-grapheme correspondences. This provides support for the type of phonics instruction that emphasises decoding at the grapheme level – that is, synthetic phonics.
Nevertheless, these results aren’t directly transferrable to an Australian classroom context. Firstly, the training was not intended to comprehensively cover the entire phonic code, since it comprised instruction in only 15 different syllable spellings. Moreover, it was delivered by experimenters – not teachers, in a lab setting – not a classroom. As such, while the results can certainly be given as evidence in favour of a certain model of instruction, we also need to keep in mind the messy research that is more representative of real life. This is the kind of research that investigates…
Things that impact on how children learn literacy
Many factors that impact on literacy development are out of a teacher’s control, such as the student’s socio-economic status, location, English language exposure, family background, and general aptitude for learning. These are also the kinds of influences that cannot be investigated through experimental manipulation. Hence, we rely on studies wherein the strength of a relationship (e.g., between Factor A and Factor B) can be statistically evaluated.
Finding a strong correlation between A and B does not mean that A causes B. After all, it could be the case that B causes A, or that A and B are linked via some third unaccounted for variable – C. These kinds of studies therefore benefit from longitudinal analyses (to better clarify the direction of causality over time) and large sample sizes (to reduce the risk of error).
One example is a study by Puranik et al. (2020), which examined the relationship between literacy skills and dialect density (i.e., the proportion of dialect use) in speakers of African American English. Spoken dialect is a complicated variable, because it is often hard to separate from other variables like socio-economic status. It is also difficult to establish what influence dialect has on literacy, because any correlation between the two could very plausibly represent the opposite direction of causality (i.e., that learning mainstream literacy skills causes a decrease in students’ use of non-mainstream spoken dialects). In other words, a simple correlation between A (dialect) and B (literacy) may reflect one or some combination of:
- A causes B
- B causes A
- C (e.g., socio-economic status) causes A and B
By investigating the relationship longitudinally, Puranik et al. (2020) showed that dialect was not only negatively correlated with literacy skills; it was negatively correlated with the growth of those skills over a one-year period. Students who were better at adapting their dialect to suit the mainstream classroom language showed greater improvements in their reading and writing skills. This certainly does not mean that the B->A and C->A/B causal relationships don’t exist, but it does provide good support for the A->B relationship also existing.
Of course, a significant factor impacting on how children learn literacy is the type of instruction they receive from teachers. Given that this is a variable we can actually control, research around instructional efficacy is incredibly important. To understand what practices work, we can look to evidence from trials of specific programs or interventions. These studies can usually be classified according to a ‘hierarchy’ of evidence:
- Level I: Systematic review / meta-analysis
- Level II: Randomised control trial
- Level III: Quasi-experimental trial
- Level IV: Case-control or cohort study
- Level V: Meta-synthesis of descriptive/qualitative studies
- Level VI: Descriptive/qualitative study
- Level VII: Opinion of authorities and/or expert committees
(University of Canberra, 2021)
All of these types of studies are useful, but they aren’t of equal value. The most reliable scientific studies are those that are least affected by confounding variables, small sample size, or bias.
As per the above list, meta-analyses are considered very reliable sources of evidence. One of the most well-known meta-analyses in the reading research world was conducted by Ehri et al. (2001). The results from this study, which were the same as those reported by the US National Reading Panel (2000), indicated that systematic phonics instruction had a significant and moderate (d = 0.41) effect on reading outcomes, based on data collated from 38 individual studies. This is strong evidence in support of delivering systematic phonics instruction to all beginning readers.
That said, and even if they are a source of Level I evidence, meta-analyses are not without their flaws, one of the main ones being that various studies of differing quality are treated equally. A randomised control trial examining a 20-week high-fidelity one-to-one intervention might fall into the same category as something much less tightly controlled and intense, as long as the program content is judged to be equivalent. As such, no one meta-analysis will give the final say on anything.
Nor will any other study, for that matter. But that’s the point of the scientific process: it’s based on an accumulation of data, often from adjacent fields of research. The outcomes are never absolute, but nuanced and dependent. Science is a web – not a single strand. All that’s needed is a little patience to tease out the knots.
Dr Nicola Bell PhD BSpPath (Hons I) is a Postdoctoral Research Fellow at MultiLit.




